41. Ramsey Plans, Time Inconsistency, Sustainable Plans#
In addition to what’s in Anaconda, this lecture will need the following libraries:
!pip install --upgrade quantecon
Show code cell output
Requirement already satisfied: quantecon in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (0.7.1)
Requirement already satisfied: numba>=0.49.0 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from quantecon) (0.57.1)
Requirement already satisfied: numpy>=1.17.0 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from quantecon) (1.24.3)
Requirement already satisfied: requests in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from quantecon) (2.31.0)
Requirement already satisfied: scipy>=1.5.0 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from quantecon) (1.11.1)
Requirement already satisfied: sympy in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from quantecon) (1.11.1)
Requirement already satisfied: llvmlite<0.41,>=0.40.0dev0 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from numba>=0.49.0->quantecon) (0.40.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from requests->quantecon) (2.0.4)
Requirement already satisfied: idna<4,>=2.5 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from requests->quantecon) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from requests->quantecon) (1.26.16)
Requirement already satisfied: certifi>=2017.4.17 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from requests->quantecon) (2023.7.22)
Requirement already satisfied: mpmath>=0.19 in /usr/share/miniconda3/envs/quantecon/lib/python3.11/site-packages (from sympy->quantecon) (1.3.0)
41.1. Overview#
This lecture describes a linear-quadratic version of a model that Guillermo Calvo [Cal78] used to illustrate the time inconsistency of optimal government plans.
Like Chang [Cha98], we use the model as a laboratory in which to explore the consequences of different timing protocols for government decision making.
The model focuses attention on intertemporal tradeoffs between
welfare benefits that anticipated deflation generates by increasing a representative agent’s liquidity as measured by his or her real money balances, and
costs associated with distorting taxes that must be used to withdraw money from the economy in order to generate anticipated deflation
The model features
rational expectations
costly government actions at all dates \(t \geq 1\) that increase household utilities at dates before \(t\)
two Bellman equations, one that expresses the private sector’s expectation of future inflation as a function of current and future government actions, another that describes the value function of a Ramsey planner
A theme of this lecture is that timing protocols affect outcomes.
We’ll use ideas from papers by Cagan [Cag56], Calvo [Cal78], Stokey [Sto89], [Sto91], Chari and Kehoe [CK90], Chang [Cha98], and Abreu [Abr88] as well as from chapter 19 of [LS18].
In addition, we’ll use ideas from linear-quadratic dynamic programming described in Linear Quadratic Control as applied to Ramsey problems in Stackelberg problems.
We specify the model in a way that allows us to use linear-quadratic dynamic programming to compute an optimal government plan under a timing protocol in which a government chooses an infinite sequence of money supply growth rates once and for all at time \(0\).
We’ll start with some imports:
import numpy as np
from quantecon import LQ
import matplotlib.pyplot as plt
%matplotlib inline
41.2. The Model#
There is no uncertainty.
Let:
\(p_t\) be the log of the price level
\(m_t\) be the log of nominal money balances
\(\theta_t = p_{t+1} - p_t\) be the net rate of inflation between \(t\) and \(t+1\)
\(\mu_t = m_{t+1} - m_t\) be the net rate of growth of nominal balances
The demand for real balances is governed by a perfect foresight version of the Cagan [Cag56] demand function:
for \(t \geq 0\).
Equation (41.1) asserts that the demand for real balances is inversely related to the public’s expected rate of inflation, which here equals the actual rate of inflation.
(When there is no uncertainty, an assumption of rational expectations implies perfect foresight).
(See [Sar77] for a rational expectations version of the model when there is uncertainty.)
Subtracting the demand function at time \(t\) from the demand function at \(t+1\) gives:
or
Because \(\alpha > 0\), \(0 < \frac{\alpha}{1+\alpha} < 1\).
Definition: For a scalar \(b_t\), let \(L^2\) be the space of sequences \(\{b_t\}_{t=0}^\infty\) satisfying
We say that a sequence that belongs to \(L^2\) is square summable.
When we assume that the sequence \(\vec \mu = \{\mu_t\}_{t=0}^\infty\) is square summable and we require that the sequence \(\vec \theta = \{\theta_t\}_{t=0}^\infty\) is square summable, the linear difference equation (41.2) can be solved forward to get:
Insight: In the spirit of Chang [Cha98], note that equations (41.1) and (41.3) show that \(\theta_t\) intermediates how choices of \(\mu_{t+j}, \ j=0, 1, \ldots\) impinge on time \(t\) real balances \(m_t - p_t = -\alpha \theta_t\).
We shall use this insight to help us simplify and analyze government policy problems.
That future rates of money creation influence earlier rates of inflation creates optimal government policy problems in which timing protocols matter.
We can rewrite the model as:
or
We write the model in the state-space form (41.4) even though \(\theta_0\) is to be determined by our model and so is not an initial condition, as it ordinarily would be in the state-space model described in our lecture on Linear Quadratic Control.
We write the model in the form (41.4) because we want to apply an approach described in our lecture on Stackelberg problems.
We assume that a government believes that a representative household’s utility of real balances at time \(t\) is:
The “bliss level” of real balances is then \(\frac{a_1}{a_2}\).
The money demand function (41.1) and the utility function (41.5) imply that utility maximizing or bliss level of real balances is attained when:
Below, we introduce the discount factor \(\beta \in (0,1)\) that a government uses to discount its future utilities.
(If we set parameters so that \(\theta^* = \log(\beta)\), then we can regard a recommendation to set \(\theta_t = \theta^*\) as a “poor man’s Friedman rule” that attains Milton Friedman’s optimal quantity of money.)
Via equation (41.3), a government plan \(\vec \mu = \{\mu_t \}_{t=0}^\infty\) leads to a sequence of inflation outcomes \(\vec \theta = \{ \theta_t \}_{t=0}^\infty\).
We assume that social costs \(\frac{c}{2} \mu_t^2\) are incurred at \(t\) when the government changes the stock of nominal money balances at rate \(\mu_t\).
Therefore, the one-period welfare function of a benevolent government is:
A benevolent government’s time \(0\) value is
We can represent the dependence of \(v_0\) on \((\vec \theta, \vec \mu)\) recursively via the difference equation
where the government’s time \(t\) continuation value \(v_t\) satisfies
41.3. Structure#
The following structure is induced by private agents’ behavior as summarized by the demand function for money (41.1) that leads to equation (41.3), which tells how future settings of \(\mu\) affect the current value of \(\theta\).
Equation (41.3) maps a policy sequence of money growth rates \(\vec \mu =\{\mu_t\}_{t=0}^\infty \in L^2\) into an inflation sequence \(\vec \theta = \{\theta_t\}_{t=0}^\infty \in L^2\).
These, in turn, induce a discounted value to a government sequence \(\vec v = \{v_t\}_{t=0}^\infty \in L^2\) that satisfies the recursion
where we have called \(s(\theta_t, \mu_t) = r(x_t, \mu_t)\), as above.
Thus, a triple of sequences \((\vec \mu, \vec \theta, \vec v)\) depends on a sequence \(\vec \mu \in L^2\).
At this point \(\vec \mu \in L^2\) is an arbitrary exogenous policy.
A theory of government decisions will make \(\vec \mu\) endogenous, i.e., a theoretical output instead of an input.
41.4. Intertemporal Structure#
Criterion function (41.7) and the constraint system (41.4) exhibit the following structure:
Setting \(\mu_t \neq 0\) imposes costs \(\frac{c}{2} \mu_t^2\) at time \(t\) and at no other times; but
The money growth rate \(\mu_t\) affects the government’s one-period utilities at all dates \(s = 0, 1, \ldots, t\).
This structure sets the stage for the emergence of a time-inconsistent optimal government plan under a Ramsey timing protocol, also called a Stackelberg timing protocol.
We’ll eventually study outcomes under a Ramsey timing protocol.
But we’ll also study the consequences of other timing protocols.
41.5. Four Models of Government Policy#
We consider four models of policymakers that differ in
what a policymaker is allowed to choose, either a sequence \(\vec \mu\) or just \(\mu_t\) in a single period \(t\).
when a policymaker chooses, either once and for all at time \(0\), or at some time or times \(t \geq 0\).
what a policymaker assumes about how its choice of \(\mu_t\) affects private agents’ expectations about earlier and later inflation rates.
In two of our models, a single policymaker chooses a sequence \(\{\mu_t\}_{t=0}^\infty\) once and for all, taking into account how \(\mu_t\) affects household one-period utilities at dates \(s = 0, 1, \ldots, t-1\)
these two models thus employ a Ramsey or Stackelberg timing protocol.
In two other models, there is a sequence of policymakers, each of whom sets \(\mu_t\) at one \(t\) only.
Each such policymaker ignores effects that its choice of \(\mu_t\) has on household one-period utilities at dates \(s = 0, 1, \ldots, t-1\).
The four models differ with respect to timing protocols, constraints on government choices, and government policymakers’ beliefs about how their decisions affect private agents’ beliefs about future government decisions.
The models are distinguished by having either
A single Ramsey planner chooses a sequence \(\{\mu_t\}_{t=0}^\infty\) once and for all at time \(0\); or
A single Ramsey planner chooses a sequence \(\{\mu_t\}_{t=0}^\infty\) once and for all at time \(0\) subject to the constraint that \(\mu_t = \mu\) for all \(t \geq 0\); or
A sequence of separate policymakers chooses \(\mu_t\) for \(t =0, 1, 2, \ldots\)
a time \(t\) policymaker chooses \(\mu_t\) only and forecasts that future government decisions are unaffected by its choice; or
A sequence of separate policymakers chooses \(\mu_t\) for \(t =0, 1, 2, \ldots\)
a time \(t\) policymaker chooses only \(\mu_t\) but believes that its choice of \(\mu_t\) shapes private agents’ beliefs about future rates of money creation and inflation, and through them, future government actions.
The relationship between outcomes in the first (Ramsey) timing protocol and the fourth timing protocol and belief structure is the subject of a literature on sustainable or credible public policies (Chari and Kehoe [CK90] [Sto89], and Stokey [Sto91]).
We’ll discuss that topic later in this lecture.
41.6. A Ramsey Planner#
First, we consider a Ramsey planner that chooses \(\{\mu_t, \theta_t\}_{t=0}^\infty\) to maximize (41.7) subject to the law of motion (41.4).
We can split this problem into two stages, as in Stackelberg problems and [LS18] Chapter 19.
In the first stage, we take the initial inflation rate \(\theta_0\) as given, and then solve the resulting LQ dynamic programming problem.
In the second stage, we maximize over the initial inflation rate \(\theta_0\).
Define a feasible set of \((\overrightarrow x_1, \overrightarrow \mu_0)\) sequences, both of which must belong to \(L^2\):
41.6.1. Subproblem 1#
The value function
satisfies the Bellman equation
subject to:
As in Stackelberg problems, we map this problem into a linear-quadratic control problem and deduce an optimal value function \(J(x)\).
Guessing that \(J(x) = - x'Px\) and substituting into the Bellman equation gives rise to the algebraic matrix Riccati equation:
and an optimal decision rule
where
The QuantEcon LQ class solves for \(F\) and \(P\) given inputs \(Q, R, A, B\), and \(\beta\).
41.6.2. Subproblem 2#
The value of the Ramsey problem is
where \(V\) is the maximum value of \(v_0\) defined in equation (41.7).
The value function
Maximizing this with respect to \(\theta_0\) yields the FOC:
which implies
41.6.3. Representation of Ramsey Plan#
The preceding calculations indicate that we can represent a Ramsey plan \(\vec \mu\) recursively with the following system created in the spirit of Chang [Cha98]:
To interpret this system, think of the sequence \(\{\theta_t\}_{t=0}^\infty\) as a sequence of synthetic promised inflation rates.
At this point, we can think of these promised inflation rates just as computational devices for generating a sequence \(\vec\mu\) of money growth rates that are to be substituted into equation (41.3) to form actual rates of inflation.
But it can be verified that if we substitute a plan \(\vec \mu = \{\mu_t\}_{t=0}^\infty\) that satisfies these equations into equation (41.3), we obtain the same sequence \(\vec \theta\) generated by the system (41.9).
(Here an application of the Big \(K\), little \(k\) trick could once again be enlightening.)
Thus, our construction of a Ramsey plan guarantees that promised inflation equals actual inflation.
41.6.4. Multiple roles of \(\theta_t\)#
The inflation rate \(\theta_t\) plays three roles simultaneously:
In equation (41.3), \(\theta_t\) is the actual rate of inflation between \(t\) and \(t+1\).
In equation (41.2) and (41.3), \(\theta_t\) is also the public’s expected rate of inflation between \(t\) and \(t+1\).
In system (41.9), \(\theta_t\) is a promised rate of inflation chosen by the Ramsey planner at time \(0\).
That the same variable \(\theta_t\) takes on these multiple roles brings insights about commitment and forward guidance, following versus leading the market, and dynamic or time inconsistency.
41.6.5. Time Inconsistency#
As discussed in Stackelberg problems and Optimal taxation with state-contingent debt, a continuation Ramsey plan is not a Ramsey plan.
This is a concise way of characterizing the time inconsistency of a Ramsey plan.
The time inconsistency of a Ramsey plan has motivated other models of government decision making that alter either
the timing protocol and/or
assumptions about how government decision makers think their decisions affect private agents’ beliefs about future government decisions
41.7. A Constrained-to-a-Constant-Growth-Rate Ramsey Government#
We now consider a peculiar model of optimal government behavior.
We created this model in order to highlight an aspect of an optimal government policy associated with its time inconsistency, namely, the feature that optimal settings of the policy instrument vary over time.
Instead of allowing the Ramsey government to choose different settings of its instrument at different moments, we now assume that at time \(0\), a Ramsey government at time \(0\) once and for all chooses a constant sequence \(\mu_t = \check \mu\) for all \(t \geq 0\) to maximize
Here we have imposed the perfect foresight outcome implied by equation (41.2) that \(\theta_t = \check \mu\) when the government chooses a constant \(\mu\) for all \(t \geq 0\).
With the quadratic form (41.5) for the utility function \(U\), the maximizing \(\bar \mu\) is
Summary: We have introduced the constrained-to-a-constant \(\mu\) government in order to highlight time-variation of \(\mu_t\) as a telltale sign of time inconsistency of a Ramsey plan.
41.8. Markov Perfect Governments#
We now alter the timing protocol by considering a sequence of government policymakers, the time \(t\) representative of which chooses \(\mu_t\) and expects all future governments to set \(\mu_{t+j} = \bar \mu\).
This assumption mirrors an assumption made in a different setting Markov Perfect Equilibrium.
A government policymaker at \(t\) believes that \(\bar \mu\) is unaffected by its choice of \(\mu_t\).
The time \(t\) rate of inflation is then:
The time \(t\) government policymaker then chooses \(\mu_t\) to maximize:
where \(V(\bar \mu)\) is the time \(0\) value \(v_0\) of recursion (41.8) under a money supply growth rate that is forever constant at \(\bar \mu\).
Substituting for \(U\) and \(\theta_t\) gives:
The first-order necessary condition for \(\mu_t\) is then:
Rearranging we get:
A Markov Perfect Equilibrium (MPE) outcome sets \(\mu_t = \bar \mu\):
In light of results presented in the previous section, this can be simplified to:
41.9. Outcomes under Three Timing Protocols#
Below we compute sequences \(\{ \theta_t,\mu_t \}\) under a Ramsey plan and compare these with the constant levels of \(\theta\) and \(\mu\) in a) a Markov Perfect Equilibrium, and b) a Ramsey plan in which the planner is restricted to choose \(\mu_t = \check\mu\) for all \(t \geq 0\).
We denote the Ramsey sequence as \(\theta^R, \mu^R\) and the MPE values as \(\theta^{MPE}, \mu^{MPE}\).
The bliss level of inflation is denoted by \(\theta^*\).
First, we will create a class ChangLQ that solves the models and stores their values
class ChangLQ:
"""
Class to solve LQ Chang model
"""
def __init__(self, α, α0, α1, α2, c, T=1000, θ_n=200):
# Record parameters
self.α, self.α0, self.α1 = α, α0, α1
self.α2, self.c, self.T, self.θ_n = α2, c, T, θ_n
# Create β using "Poor Man's Friedman Rule"
self.β = np.exp(-α1 / (α * α2))
# Solve the Ramsey Problem #
# LQ Matrices
R = -np.array([[α0, -α1 * α / 2],
[-α1 * α/2, -α2 * α**2 / 2]])
Q = -np.array([[-c / 2]])
A = np.array([[1, 0], [0, (1 + α) / α]])
B = np.array([[0], [-1 / α]])
# Solve LQ Problem (Subproblem 1)
lq = LQ(Q, R, A, B, beta=self.β)
self.P, self.F, self.d = lq.stationary_values()
# Solve Subproblem 2
self.θ_R = -self.P[0, 1] / self.P[1, 1]
# Find bliss level of θ
self.θ_B = np.log(self.β)
# Solve the Markov Perfect Equilibrium
self.μ_MPE = -α1 / ((1 + α) / α * c + α / (1 + α)
* α2 + α**2 / (1 + α) * α2)
self.θ_MPE = self.μ_MPE
self.μ_check = -α * α1 / (α2 * α**2 + c)
# Calculate value under MPE and Check economy
self.J_MPE = (α0 + α1 * (-α * self.μ_MPE) - α2 / 2
* (-α * self.μ_MPE)**2 - c/2 * self.μ_MPE**2) / (1 - self.β)
self.J_check = (α0 + α1 * (-α * self.μ_check) - α2/2
* (-α * self.μ_check)**2 - c / 2 * self.μ_check**2) \
/ (1 - self.β)
# Simulate Ramsey plan for large number of periods
θ_series = np.vstack((np.ones((1, T)), np.zeros((1, T))))
μ_series = np.zeros(T)
J_series = np.zeros(T)
θ_series[1, 0] = self.θ_R
μ_series[0] = -self.F.dot(θ_series[:, 0])
J_series[0] = -θ_series[:, 0] @ self.P @ θ_series[:, 0].T
for i in range(1, T):
θ_series[:, i] = (A - B @ self.F) @ θ_series[:, i-1]
μ_series[i] = -self.F @ θ_series[:, i]
J_series[i] = -θ_series[:, i] @ self.P @ θ_series[:, i].T
self.J_series = J_series
self.μ_series = μ_series
self.θ_series = θ_series
# Find the range of θ in Ramsey plan
θ_LB = min(θ_series[1, :])
θ_LB = min(θ_LB, self.θ_B)
θ_UB = max(θ_series[1, :])
θ_UB = max(θ_UB, self.θ_MPE)
θ_range = θ_UB - θ_LB
self.θ_LB = θ_LB - 0.05 * θ_range
self.θ_UB = θ_UB + 0.05 * θ_range
self.θ_range = θ_range
# Find value function and policy functions over range of θ
θ_space = np.linspace(self.θ_LB, self.θ_UB, 200)
J_space = np.zeros(200)
check_space = np.zeros(200)
μ_space = np.zeros(200)
θ_prime = np.zeros(200)
for i in range(200):
J_space[i] = - np.array((1, θ_space[i])) \
@ self.P @ np.array((1, θ_space[i])).T
μ_space[i] = - self.F @ np.array((1, θ_space[i]))
x_prime = (A - B @ self.F) @ np.array((1, θ_space[i]))
θ_prime[i] = x_prime[1]
check_space[i] = (α0 + α1 * (-α * θ_space[i]) -
α2/2 * (-α * θ_space[i])**2 - c/2 * θ_space[i]**2) / (1 - self.β)
J_LB = min(J_space)
J_UB = max(J_space)
J_range = J_UB - J_LB
self.J_LB = J_LB - 0.05 * J_range
self.J_UB = J_UB + 0.05 * J_range
self.J_range = J_range
self.J_space = J_space
self.θ_space = θ_space
self.μ_space = μ_space
self.θ_prime = θ_prime
self.check_space = check_space
We will create an instance of ChangLQ with the following parameters
clq = ChangLQ(α=1, α0=1, α1=0.5, α2=3, c=2)
clq.β
0.8464817248906141
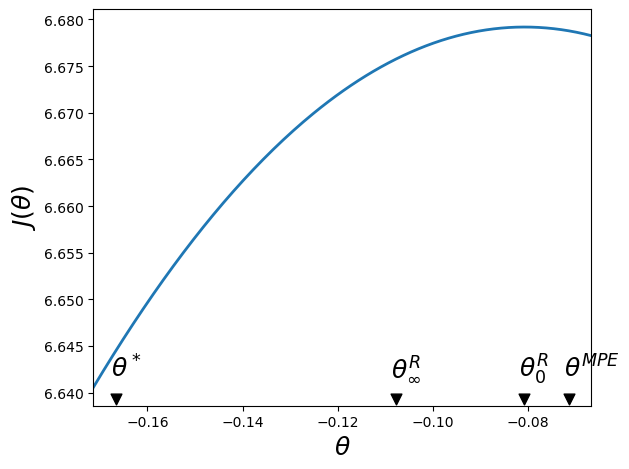
The following code generates a figure that plots the value function from the Ramsey Planner’s problem, which is maximized at \(\theta^R_0\).
The figure also shows the limiting value \(\theta_\infty^R\) to which the inflation rate \(\theta_t\) converges under the Ramsey plan and compares it to the MPE value and the bliss value.
def plot_value_function(clq):
"""
Method to plot the value function over the relevant range of θ
Here clq is an instance of ChangLQ
"""
fig, ax = plt.subplots()
ax.set_xlim([clq.θ_LB, clq.θ_UB])
ax.set_ylim([clq.J_LB, clq.J_UB])
# Plot value function
ax.plot(clq.θ_space, clq.J_space, lw=2)
plt.xlabel(r"$\theta$", fontsize=18)
plt.ylabel(r"$J(\theta)$", fontsize=18)
t1 = clq.θ_space[np.argmax(clq.J_space)]
tR = clq.θ_series[1, -1]
θ_points = [t1, tR, clq.θ_B, clq.θ_MPE]
labels = [r"$\theta_0^R$", r"$\theta_\infty^R$",
r"$\theta^*$", r"$\theta^{MPE}$"]
# Add points for θs
for θ, label in zip(θ_points, labels):
ax.scatter(θ, clq.J_LB + 0.02 * clq.J_range, 60, 'black', 'v')
ax.annotate(label,
xy=(θ, clq.J_LB + 0.01 * clq.J_range),
xytext=(θ - 0.01 * clq.θ_range,
clq.J_LB + 0.08 * clq.J_range),
fontsize=18)
plt.tight_layout()
plt.show()
plot_value_function(clq)
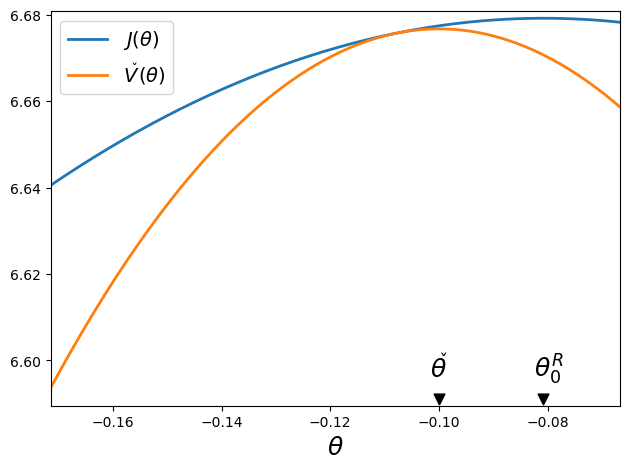
The next code generates a figure that plots the value function from the Ramsey Planner’s problem as well as that for a Ramsey planner that must choose a constant \(\mu\) (that in turn equals an implied constant \(\theta\)).
def compare_ramsey_check(clq):
"""
Method to compare values of Ramsey and Check
Here clq is an instance of ChangLQ
"""
fig, ax = plt.subplots()
check_min = min(clq.check_space)
check_max = max(clq.check_space)
check_range = check_max - check_min
check_LB = check_min - 0.05 * check_range
check_UB = check_max + 0.05 * check_range
ax.set_xlim([clq.θ_LB, clq.θ_UB])
ax.set_ylim([check_LB, check_UB])
ax.plot(clq.θ_space, clq.J_space, lw=2, label=r"$J(\theta)$")
plt.xlabel(r"$\theta$", fontsize=18)
ax.plot(clq.θ_space, clq.check_space,
lw=2, label=r"$V^\check(\theta)$")
plt.legend(fontsize=14, loc='upper left')
θ_points = [clq.θ_space[np.argmax(clq.J_space)],
clq.μ_check]
labels = [r"$\theta_0^R$", r"$\theta^\check$"]
for θ, label in zip(θ_points, labels):
ax.scatter(θ, check_LB + 0.02 * check_range, 60, 'k', 'v')
ax.annotate(label,
xy=(θ, check_LB + 0.01 * check_range),
xytext=(θ - 0.02 * check_range,
check_LB + 0.08 * check_range),
fontsize=18)
plt.tight_layout()
plt.show()
compare_ramsey_check(clq)
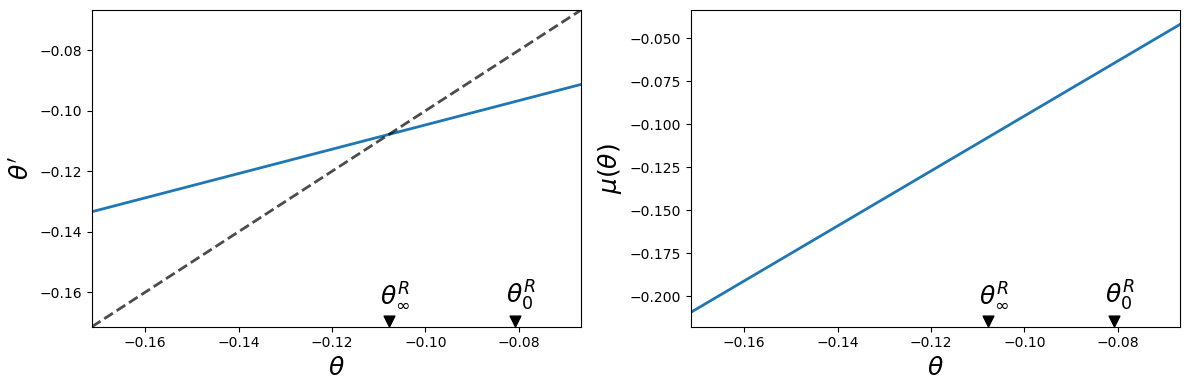
The next code generates figures that plot the policy functions for a continuation Ramsey planner.
The left figure shows the choice of \(\theta'\) chosen by a continuation Ramsey planner who inherits \(\theta\).
The right figure plots a continuation Ramsey planner’s choice of \(\mu\) as a function of an inherited \(\theta\).
def plot_policy_functions(clq):
"""
Method to plot the policy functions over the relevant range of θ
Here clq is an instance of ChangLQ
"""
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
labels = [r"$\theta_0^R$", r"$\theta_\infty^R$"]
ax = axes[0]
ax.set_ylim([clq.θ_LB, clq.θ_UB])
ax.plot(clq.θ_space, clq.θ_prime,
label=r"$\theta'(\theta)$", lw=2)
x = np.linspace(clq.θ_LB, clq.θ_UB, 5)
ax.plot(x, x, 'k--', lw=2, alpha=0.7)
ax.set_ylabel(r"$\theta'$", fontsize=18)
θ_points = [clq.θ_space[np.argmax(clq.J_space)],
clq.θ_series[1, -1]]
for θ, label in zip(θ_points, labels):
ax.scatter(θ, clq.θ_LB + 0.02 * clq.θ_range, 60, 'k', 'v')
ax.annotate(label,
xy=(θ, clq.θ_LB + 0.01 * clq.θ_range),
xytext=(θ - 0.02 * clq.θ_range,
clq.θ_LB + 0.08 * clq.θ_range),
fontsize=18)
ax = axes[1]
μ_min = min(clq.μ_space)
μ_max = max(clq.μ_space)
μ_range = μ_max - μ_min
ax.set_ylim([μ_min - 0.05 * μ_range, μ_max + 0.05 * μ_range])
ax.plot(clq.θ_space, clq.μ_space, lw=2)
ax.set_ylabel(r"$\mu(\theta)$", fontsize=18)
for ax in axes:
ax.set_xlabel(r"$\theta$", fontsize=18)
ax.set_xlim([clq.θ_LB, clq.θ_UB])
for θ, label in zip(θ_points, labels):
ax.scatter(θ, μ_min - 0.03 * μ_range, 60, 'black', 'v')
ax.annotate(label, xy=(θ, μ_min - 0.03 * μ_range),
xytext=(θ - 0.02 * clq.θ_range,
μ_min + 0.03 * μ_range),
fontsize=18)
plt.tight_layout()
plt.show()
plot_policy_functions(clq)
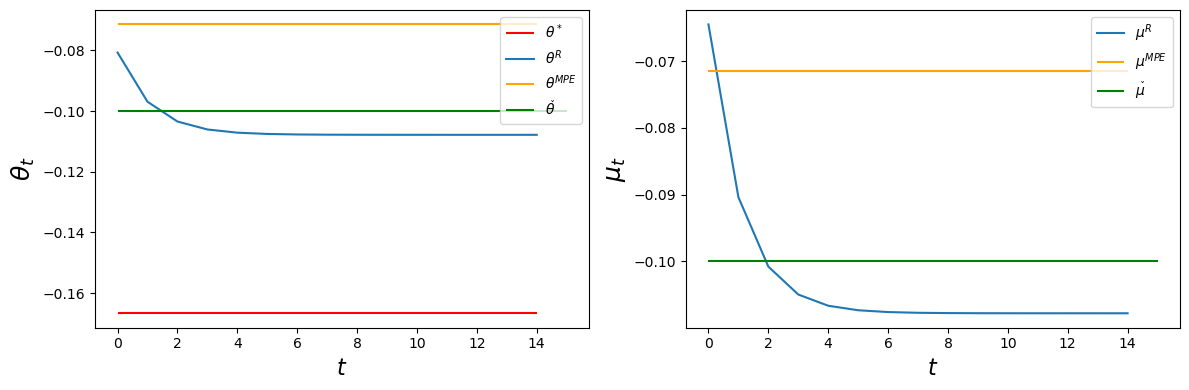
The following code generates a figure that plots sequences of \(\mu\) and \(\theta\) in the Ramsey plan and compares these to the constant levels in a MPE and in a Ramsey plan with a government restricted to set \(\mu_t\) to a constant for all \(t\).
def plot_ramsey_MPE(clq, T=15):
"""
Method to plot Ramsey plan against Markov Perfect Equilibrium
Here clq is an instance of ChangLQ
"""
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
plots = [clq.θ_series[1, 0:T], clq.μ_series[0:T]]
MPEs = [clq.θ_MPE, clq.μ_MPE]
labels = [r"\theta", r"\mu"]
axes[0].hlines(clq.θ_B, 0, T-1, 'r', label=r"$\theta^*$")
for ax, plot, MPE, label in zip(axes, plots, MPEs, labels):
ax.plot(plot, label=r"$" + label + "^R$")
ax.hlines(MPE, 0, T-1, 'orange', label=r"$" + label + "^{MPE}$")
ax.hlines(clq.μ_check, 0, T, 'g', label=r"$" + label + "^\check$")
ax.set_xlabel(r"$t$", fontsize=16)
ax.set_ylabel(r"$" + label + "_t$", fontsize=18)
ax.legend(loc='upper right')
plt.tight_layout()
plt.show()
plot_ramsey_MPE(clq)
41.9.1. Time Inconsistency of Ramsey Plan#
The variation over time in \(\vec \mu\) chosen by the Ramsey planner is a symptom of time inconsistency.
The Ramsey planner reaps immediate benefits from promising lower inflation later to be achieved by costly distorting taxes.
These benefits are intermediated by reductions in expected inflation that precede the reductions in money creation rates that rationalize them, as indicated by equation (41.3).
A government authority offered the opportunity to ignore effects on past utilities and to reoptimize at date \(t \geq 1\) would, if allowed, want to deviate from a Ramsey plan.
Note: A modified Ramsey plan constructed under the restriction that \(\mu_t\) must be constant over time is time consistent (see \(\check \mu\) and \(\check \theta\) in the above graphs).
41.9.2. Meaning of Time Inconsistency#
In settings in which governments actually choose sequentially, many economists regard a time inconsistent plan as implausible because of the incentives to deviate that are presented along the plan.
A way to summarize this defect in a Ramsey plan is to say that it is not credible because there endure incentives for policymakers to deviate from it.
For that reason, the Markov perfect equilibrium concept attracts many economists.
A Markov perfect equilibrium plan is constructed to insure that government policymakers who choose sequentially do not want to deviate from it.
The no incentive to deviate from the plan property is what makes the Markov perfect equilibrium concept attractive.
41.9.3. Ramsey Plans Strike Back#
Research by Abreu [Abr88], Chari and Kehoe [CK90] [Sto89], and Stokey [Sto91] discovered conditions under which a Ramsey plan can be rescued from the complaint that it is not credible.
They accomplished this by expanding the description of a plan to include expectations about adverse consequences of deviating from it that can serve to deter deviations.
We turn to such theories of sustainable plans next.
41.10. A Fourth Model of Government Decision Making#
This is a model in which
the government chooses \(\{\mu_t\}_{t=0}^\infty\) not once and for all at \(t=0\) but chooses to set \(\mu_t\) at time \(t\), not before.
private agents’ forecasts of \(\{\mu_{t+j+1}, \theta_{t+j+1}\}_{j=0}^\infty\) respond to whether the government at \(t\) confirms or disappoints their forecasts of \(\mu_t\) brought into period \(t\) from period \(t-1\).
the government at each time \(t\) understands how private agents’ forecasts will respond to its choice of \(\mu_t\).
at each \(t\), the government chooses \(\mu_t\) to maximize a continuation discounted utility.
41.10.1. A Theory of Government Decision Making#
\(\vec \mu\) is chosen by a sequence of government decision makers, one for each \(t \geq 0\).
We assume the following within-period and between-period timing protocol for each \(t \geq 0\):
at time \(t-1\), private agents expect that the government will set \(\mu_t = \tilde \mu_t\), and more generally that it will set \(\mu_{t+j} = \tilde \mu_{t+j}\) for all \(j \geq 0\).
The forecasts \(\{\tilde \mu_{t+j}\}_{j \geq 0}\) determine a \(\theta_t = \tilde \theta_t\) and an associated log of real balances \(m_t - p_t = -\alpha\tilde \theta_t\) at \(t\).
Given those expectations and an associated \(\theta_t = \tilde \theta_t\), at \(t\) a government is free to set \(\mu_t \in {\bf R}\).
If the government at \(t\) confirms private agents’ expectations by setting \(\mu_t = \tilde \mu_t\) at time \(t\), private agents expect the continuation government policy \(\{\tilde \mu_{t+j+1}\}_{j=0}^\infty\) and therefore bring expectation \(\tilde \theta_{t+1}\) into period \(t+1\).
If the government at \(t\) disappoints private agents by setting \(\mu_t \neq \tilde \mu_t\), private agents expect \(\{\mu^A_j\}_{j=0}^\infty\) as the continuation policy for \(t+1\), i.e., \(\{\mu_{t+j+1}\} = \{\mu_j^A \}_{j=0}^\infty\) and therefore expect an associated \(\theta_0^A\) for \(t+1\). Here \(\vec \mu^A = \{\mu_j^A \}_{j=0}^\infty\) is an alternative government plan to be described below.
41.10.2. Temptation to Deviate from Plan#
The government’s one-period return function \(s(\theta,\mu)\) described in equation (41.6) above has the property that for all \(\theta\)
This inequality implies that whenever the policy calls for the government to set \(\mu \neq 0\), the government could raise its one-period payoff by setting \(\mu =0\).
Disappointing private sector expectations in that way would increase the government’s current payoff but would have adverse consequences for subsequent government payoffs because the private sector would alter its expectations about future settings of \(\mu\).
The temporary gain constitutes the government’s temptation to deviate from a plan.
If the government at \(t\) is to resist the temptation to raise its current payoff, it is only because it forecasts adverse consequences that its setting of \(\mu_t\) would bring for continuation government payoffs via alterations in the private sector’s expectations.
41.11. Sustainable or Credible Plan#
We call a plan \(\vec \mu\) sustainable or credible if at each \(t \geq 0\) the government chooses to confirm private agents’ prior expectation of its setting for \(\mu_t\).
The government will choose to confirm prior expectations only if the long-term loss from disappointing private sector expectations – coming from the government’s understanding of the way the private sector adjusts its expectations in response to having its prior expectations at \(t\) disappointed – outweigh the short-term gain from disappointing those expectations.
The theory of sustainable or credible plans assumes throughout that private sector expectations about what future governments will do are based on the assumption that governments at times \(t \geq 0\) always act to maximize the continuation discounted utilities that describe those governments’ purposes.
This aspect of the theory means that credible plans always come in pairs:
a credible (continuation) plan to be followed if the government at \(t\) confirms private sector expectations
a credible plan to be followed if the government at \(t\) disappoints private sector expectations
That credible plans come in pairs threaten to bring an explosion of plans to keep track of
each credible plan itself consists of two credible plans
therefore, the number of plans underlying one plan is unbounded
But Dilip Abreu showed how to render manageable the number of plans that must be kept track of.
The key is an object called a self-enforcing plan.
41.11.1. Abreu’s Self-Enforcing Plan#
A plan \(\vec \mu^A\) (here the superscipt \(A\) is for Abreu) is said to be self-enforcing if
the consequence of disappointing private agents’ expectations at time \(j\) is to restart plan \(\vec \mu^A\) at time \(j+1\)
the consequence of restarting the plan is sufficiently adverse that it forever deters all deviations from the plan
More precisely, a government plan \(\vec \mu^A\) with equilibrium inflation sequence \(\vec \theta^A\) is self-enforcing if
(Here it is useful to recall that setting \(\mu=0\) is the maximizing choice for the government’s one-period return function)
The first line tells the consequences of confirming private agents’ expectations by following the plan, while the second line tells the consequences of disappointing private agents’ expectations by deviating from the plan.
A consequence of the inequality stated in the definition is that a self-enforcing plan is credible.
Self-enforcing plans can be used to construct other credible plans, including ones with better values.
Thus, where \(\vec v^A\) is the value associated with a self-enforcing plan \(\vec \mu^A\), a sufficient condition for another plan \(\vec \mu\) associated with inflation \(\vec \theta\) and value \(\vec v\) to be credible is that
For this condition to be satisfied it is necessary and sufficient that
The left side of the above inequality is the government’s gain from deviating from the plan, while the right side is the government’s loss from deviating from the plan.
A government never wants to deviate from a credible plan.
Abreu taught us that key step in constructing a credible plan is first constructing a self-enforcing plan that has a low time \(0\) value.
The idea is to use the self-enforcing plan as a continuation plan whenever the government’s choice at time \(t\) fails to confirm private agents’ expectation.
We shall use a construction featured in Abreu ([Abr88]) to construct a self-enforcing plan with low time \(0\) value.
41.11.2. Abreu Carrot-Stick Plan#
Abreu ([Abr88]) invented a way to create a self-enforcing plan with a low initial value.
Imitating his idea, we can construct a self-enforcing plan \(\vec \mu\) with a low time \(0\) value to the government by insisting that future government decision makers set \(\mu_t\) to a value yielding low one-period utilities to the household for a long time, after which government decisions thereafter yield high one-period utilities.
Low one-period utilities early are a stick
High one-period utilities later are a carrot
Consider a candidate plan \(\vec \mu^A\) that sets \(\mu_t^A = \bar \mu\) (a high positive number) for \(T_A\) periods, and then reverts to the Ramsey plan.
Denote this sequence by \(\{\mu_t^A\}_{t=0}^\infty\).
The sequence of inflation rates implied by this plan, \(\{\theta_t^A\}_{t=0}^\infty\), can be calculated using:
The value of \(\{\theta_t^A,\mu_t^A \}_{t=0}^\infty\) at time \(0\) is
For an appropriate \(T_A\), this plan can be verified to be self-enforcing and therefore credible.
41.11.3. Example of Self-Enforcing Plan#
The following example implements an Abreu stick-and-carrot plan.
The government sets \(\mu_t^A = 0.1\) for \(t=0, 1, \ldots, 9\) and then starts the Ramsey plan.
We have computed outcomes for this plan.
For this plan, we plot the \(\theta^A\), \(\mu^A\) sequences as well as the implied \(v^A\) sequence.
Notice that because the government sets money supply growth high for 10 periods, inflation starts high.
Inflation gradually slowly declines because people expect the government to lower the money growth rate after period \(10\).
From the 10th period onwards, the inflation rate \(\theta^A_t\) associated with this Abreu plan starts the Ramsey plan from its beginning, i.e., \(\theta^A_{t+10} =\theta^R_t \ \ \forall t \geq 0\).
def abreu_plan(clq, T=1000, T_A=10, μ_bar=0.1, T_Plot=20):
# Append Ramsey μ series to stick μ series
clq.μ_A = np.append(np.full(T_A, μ_bar), clq.μ_series[:-T_A])
# Calculate implied stick θ series
clq.θ_A = np.zeros(T)
discount = np.zeros(T)
for t in range(T):
discount[t] = (clq.α / (1 + clq.α))**t
for t in range(T):
length = clq.μ_A[t:].shape[0]
clq.θ_A[t] = 1 / (clq.α + 1) * sum(clq.μ_A[t:] * discount[0:length])
# Calculate utility of stick plan
U_A = np.zeros(T)
for t in range(T):
U_A[t] = clq.β**t * (clq.α0 + clq.α1 * (-clq.θ_A[t])
- clq.α2 / 2 * (-clq.θ_A[t])**2 - clq.c * clq.μ_A[t]**2)
clq.V_A = np.zeros(T)
for t in range(T):
clq.V_A[t] = sum(U_A[t:] / clq.β**t)
# Make sure Abreu plan is self-enforcing
clq.V_dev = np.zeros(T_Plot)
for t in range(T_Plot):
clq.V_dev[t] = (clq.α0 + clq.α1 * (-clq.θ_A[t])
- clq.α2 / 2 * (-clq.θ_A[t])**2) \
+ clq.β * clq.V_A[0]
fig, axes = plt.subplots(3, 1, figsize=(8, 12))
axes[2].plot(clq.V_dev[0:T_Plot], label="$V^{A, D}_t$", c="orange")
plots = [clq.θ_A, clq.μ_A, clq.V_A]
labels = [r"$\theta_t^A$", r"$\mu_t^A$", r"$V^A_t$"]
for plot, ax, label in zip(plots, axes, labels):
ax.plot(plot[0:T_Plot], label=label)
ax.set(xlabel="$t$", ylabel=label)
ax.legend()
plt.tight_layout()
plt.show()
abreu_plan(clq)
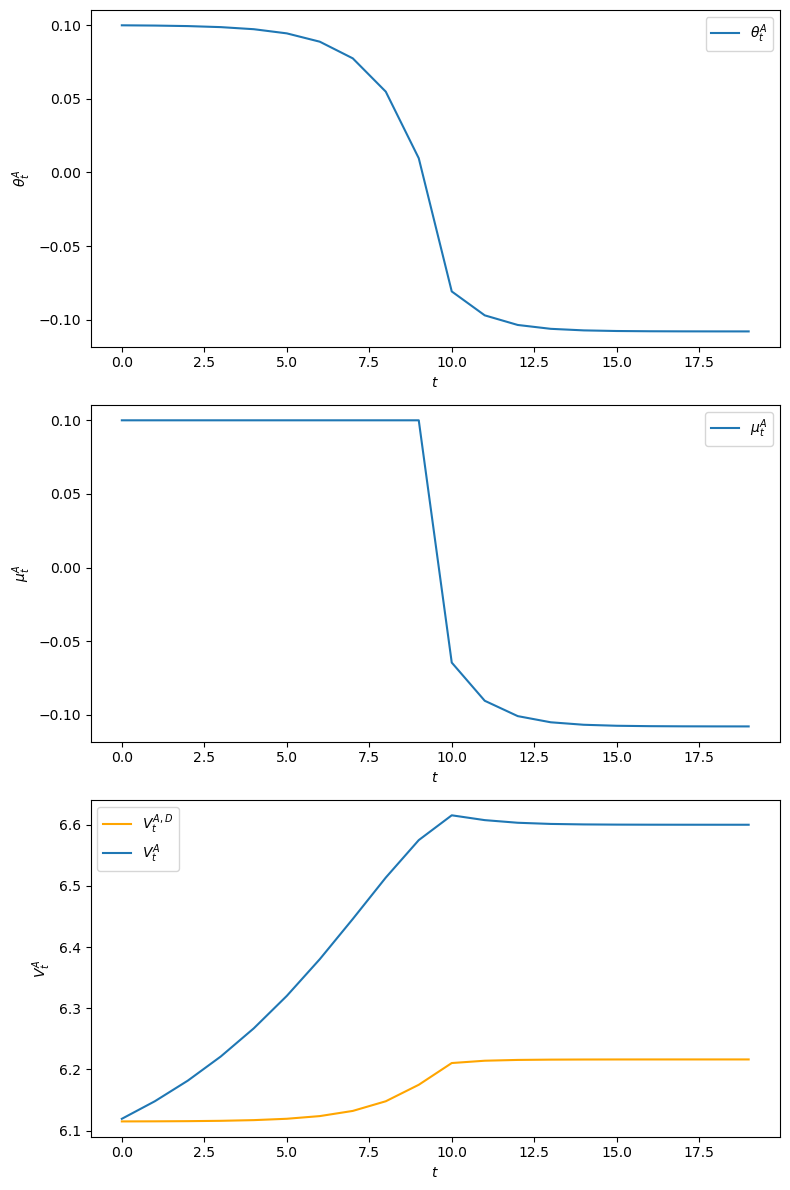
To confirm that the plan \(\vec \mu^A\) is self-enforcing, we plot an object that we call \(V_t^{A,D}\), defined in the key inequality in the second line of equation (41.10) above.
\(V_t^{A,D}\) is the value at \(t\) of deviating from the self-enforcing plan \(\vec \mu^A\) by setting \(\mu_t = 0\) and then restarting the plan at \(v^A_0\) at \(t+1\):
In the above graph \(v_t^A > v_t^{A,D}\), which confirms that \(\vec \mu^A\) is a self-enforcing plan.
We can also verify the inequalities required for \(\vec \mu^A\) to be self-confirming numerically as follows
np.all(clq.V_A[0:20] > clq.V_dev[0:20])
True
Given that plan \(\vec \mu^A\) is self-enforcing, we can check that the Ramsey plan \(\vec \mu^R\) is credible by verifying that:
def check_ramsey(clq, T=1000):
# Make sure Ramsey plan is sustainable
R_dev = np.zeros(T)
for t in range(T):
R_dev[t] = (clq.α0 + clq.α1 * (-clq.θ_series[1, t])
- clq.α2 / 2 * (-clq.θ_series[1, t])**2) \
+ clq.β * clq.V_A[0]
return np.all(clq.J_series > R_dev)
check_ramsey(clq)
True
41.11.4. Recursive Representation of a Sustainable Plan#
We can represent a sustainable plan recursively by taking the continuation value \(v_t\) as a state variable.
We form the following 3-tuple of functions:
In addition to these equations, we need an initial value \(v_0\) to characterize a sustainable plan.
The first equation of (41.12) tells the recommended value of \(\hat \mu_t\) as a function of the promised value \(v_t\).
The second equation of (41.12) tells the inflation rate as a function of \(v_t\).
The third equation of (41.12) updates the continuation value in a way that depends on whether the government at \(t\) confirms private agents’ expectations by setting \(\mu_t\) equal to the recommended value \(\hat \mu_t\), or whether it disappoints those expectations.
41.12. Whose Credible Plan is it?#
A credible government plan \(\vec \mu\) plays multiple roles.
It is a sequence of actions chosen by the government.
It is a sequence of private agents’ forecasts of government actions.
Thus, \(\vec \mu\) is both a government policy and a collection of private agents’ forecasts of government policy.
Does the government choose policy actions or does it simply confirm prior private sector forecasts of those actions?
An argument in favor of the government chooses interpretation comes from noting that the theory of credible plans builds in a theory that the government each period chooses the action that it wants.
An argument in favor of the simply confirm interpretation is gathered from staring at the key inequality (41.11) that defines a credible policy.
41.13. Comparison of Equilibrium Values#
We have computed plans for
an ordinary (unrestricted) Ramsey planner who chooses a sequence \(\{\mu_t\}_{t=0}^\infty\) at time \(0\)
a Ramsey planner restricted to choose a constant \(\mu\) for all \(t \geq 0\)
a Markov perfect sequence of governments
Below we compare equilibrium time zero values for these three.
We confirm that the value delivered by the unrestricted Ramsey planner exceeds the value delivered by the restricted Ramsey planner which in turn exceeds the value delivered by the Markov perfect sequence of governments.
clq.J_series[0]
6.67918822960449
clq.J_check
6.676729524674898
clq.J_MPE
6.663435886995107
We have also computed credible plans for a government or sequence of governments that choose sequentially.
These include
a self-enforcing plan that gives a low initial value \(v_0\).
a better plan – possibly one that attains values associated with Ramsey plan – that is not self-enforcing.
41.14. Note on Dynamic Programming Squared#
The theory deployed in this lecture is an application of what we nickname dynamic programming squared.
The nickname refers to the feature that a value satisfying one Bellman equation appears as an argument in a second Bellman equation.
Thus, our models have involved two Bellman equations:
equation (41.1) expresses how \(\theta_t\) depends on \(\mu_t\) and \(\theta_{t+1}\)
equation (41.4) expresses how value \(v_t\) depends on \((\mu_t, \theta_t)\) and \(v_{t+1}\)
A value \(\theta\) from one Bellman equation appears as an argument of a second Bellman equation for another value \(v\).